
NVIDIA, KRAFTON, NC e os atuais campeões de 'League of Legends' T1 celebram o RTX Spark nos PC Bangs da Coreia
Na GTC Taipei na COMPUTEX na semana passada, a NVIDIA revelou o RTX Spark, o superchip que reinventa os PCs Windows para a era dos agentes pessoais de AI. Após este anúncio, o fundador e CEO da NVIDIA, Jensen Huang, foi para a Coreia do Sul, onde apresentou o RTX Spark à apaixonada comunidade de jogos do país. Desenvolvedores de jogos líderes — [...]

Cinco laboratórios, cinco mentes: construindo um drama financeiro multimodelos com modelos pequenos
Cinco laboratórios, cinco mentes: construindo um drama financeiro multimodelos com modelos pequenos

Modelos de fronteira OpenAI e Codex já estão disponíveis na AWS
Os modelos de fronteira OpenAI e o Codex agora estão geralmente disponíveis na AWS, oferecendo às empresas um novo caminho para construir com a OpenAI através dos ambientes, controles e fluxos de trabalho de aquisição da AWS que elas já utilizam. Clientes podem começar a usar OpenAI na AWS e ir mais rápido da avaliação à produção.

Construindo a infraestrutura para a Era da Inteligência em Michigan
OpenAI inicia a construção de um projeto de data center de 1GW em Michigan como parte do Stargate, construindo infraestrutura de AI para expandir o acesso, criar empregos e apoiar comunidades.

Nossas visões sobre políticas de IA e defesa política
Nossa abordagem em relação a políticas de IA e defesa política, transparência, apoio a uma regulamentação consciente e segurança da IA, e que nenhum grupo político externo fala em nome da empresa.

Avançando a segurança e as oportunidades para jovens através da liderança global
A OpenAI apela por uma ação global sobre a segurança de IA para jovens, propondo um instituto internacional para fortalecer as salvaguardas, os padrões e as oportunidades para os jovens.

Codex para cada função, ferramenta e fluxo de trabalho
Descubra novos plugins, sites e anotações do Codex que ajudam analistas, profissionais de marketing, designers, investidores e outras equipes a fazer mais com AI.

Travelers implementa sinistros impulsionados por IA em todo o país com OpenAI
A Travelers construiu um Assistente de Sinistros impulsionado por IA com a OpenAI para guiar os clientes no registro de sinistros, fornecer suporte 24 horas por dia, 7 dias por semana e escalar as operações durante picos de demanda.

Um projeto para a governança democrática da IA de fronteira
A OpenAI apresenta um projeto para a governança dos EUA sobre IA de fronteira, propondo uma estrutura federal para segurança, resiliência e segurança nacional.

Como a Wasmer usou o Codex para construir um runtime Node.js para edge
Veja como a Wasmer usou o Codex com GPT-5.5 para construir um runtime Node.js para edge, acelerando o desenvolvimento em 10x a 20x e entregando em semanas em vez de meses.

Apresentando novas capacidades ao GPT-Rosalind
O GPT-Rosalind aprimora a pesquisa em ciências da vida com raciocínio biológico avançado, expertise em química medicinal, análise genômica e capacidades de fluxo de trabalho experimental.

Biossegurança na Era da Inteligência
Um plano de ação para resiliência biológica impulsionada por IA

Sonhar: Memória melhor para um ChatGPT mais útil
O ChatGPT está introduzindo um novo sistema de memória para lembrar melhor as preferências, mantendo o contexto fresco e relevante em todas as conversas.

Como a Endava está redesenhando a entrega de software com base em agentes de IA
Saiba como a Endava está usando agentes de IA, ChatGPT Enterprise e Codex para acelerar a entrega de software, automatizar fluxos de trabalho e construir uma cultura nativa de IA em toda a empresa.

As últimas notícias sobre IA que anunciamos em maio de 2026
<img src="https://storage.googleapis.com/gweb-uniblog-publish-prod/images/May_AI_Recap_still.max-600x600.format-webp.webp">Aqui estão as últimas atualizações de AI do Google de maio de 2026

Propósito de Seul: Como a NVIDIA e a Coreia do Sul estão Construindo o Futuro da AI
Lar de uma infraestrutura soberana de AI de ponta e inovadores em robótica, bem como uma das comunidades de jogos mais apaixonadas do mundo, a Coreia do Sul é um dos centros globais de AI. O fundador e CEO da NVIDIA, Jensen Huang, está em Seul esta semana para se encontrar com os parceiros e construtores por trás desse trabalho. Fique ligado aqui para […] atualizações ao vivo.

Nemotron 3.5 Content Safety: Segurança Multimodal Customizável para IA Empresarial Global
Nemotron 3.5 Content Safety: Segurança Multimodal Customizável para IA Empresarial Global
Previsão: Diversão à Frente — 18 Jogos Chegam em Junho para Transmissão no GeForce NOW
A previsão de junho com GeForce NOW: 100% de chance de jogar. O GeForce NOW está alinhando novas aventuras para o mês, desde grandes blockbusters a indies peculiares prontos para o destaque. Os membros podem mergulhar em novos mundos, formar equipes em novas playlists e descobrir jogos favoritos de “só mais uma rodada” – tudo transmitido da nuvem, sem downloads [...]

EVA-Bench Data 2.0: 3 Domínios, 121 Ferramentas, 213 Cenários
Apresentamos o EVA-Bench Data 2.0, um conjunto de dados abrangente para avaliação de grandes modelos de linguagem (LLMs) em cenários complexos do mundo real. Ele abrange três domínios principais: IA para Ciência, IA para Engenharia e IA para Negócios. Com um total de 121 ferramentas e 213 cenários distintos, o EVA-Bench Data 2.0 oferece uma plataforma robusta para testar a capacidade dos LLMs de planejar, usar ferramentas e resolver problemas multimodais em contextos práticos. Este trabalho detalha a metodologia de construção do conjunto de dados, as características de seus domínios e as ferramentas integradas, destacando seu potencial para impulsionar o avanço da pesquisa em LLMs e IA.

Projetando a CLI do HF como uma maneira otimizada para agentes trabalharem com o Hub
A interface de linha de comando (CLI) do Hugging Face, ou 'hf CLI', é uma ferramenta poderosa para interagir com o Hugging Face Hub (o Hub). Originalmente projetada para usuários humanos, a CLI do HF contém muitos recursos construídos para automação. Esta postagem do blog explora a evolução da CLI do HF e como ela está sendo aprimorada para melhor atender à crescente necessidade de agentes de IA interagirem programaticamente com o Hub. Ao otimizar a CLI do HF para agentes, facilitamos o acesso e a utilização dos vastos recursos do Hub para sistemas de IA autônomos e semi-autônomos, promovendo o desenvolvimento de aplicações mais inteligentes e eficientes.

NVIDIA Research Desbloqueia Manipulação Avançada, Direção Autônoma Mais Inteligente e Treinamento de Agentes em Escala
O que torna uma garra robótica útil não é que ela possa pegar um objeto — é que ela pode pegar o próximo, e o que vem depois, com uma ferramenta que nunca usou antes. O que torna um sistema de veículo autônomo seguro não é apenas que ele pode deliberar sobre uma situação — é que […]
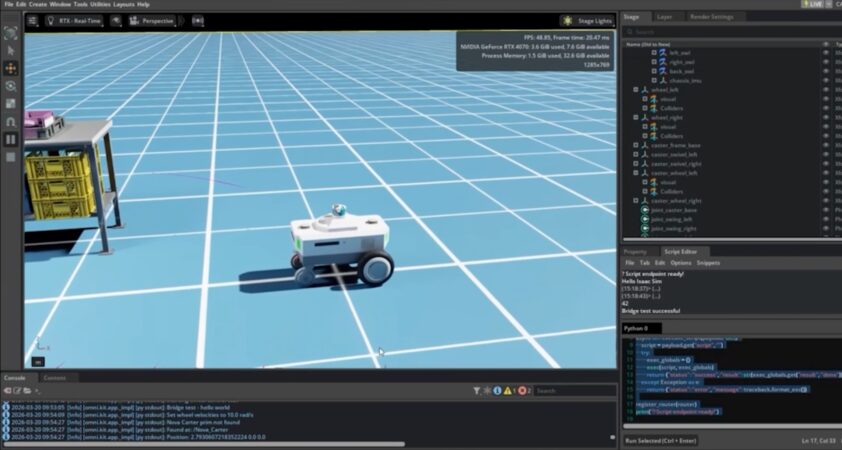
NVIDIA Possibilita a Próxima Era da Pesquisa em IA Física com Habilidades de Agente para Veículos Autônomos, Robótica e Visão Computacional
Na CVPR, a NVIDIA está revelando novas habilidades de agente de IA física que ajudam pesquisadores e desenvolvedores a acelerar o desenvolvimento de veículos autônomos, robôs e sistemas de visão computacional. O principal desafio na pesquisa em IA física não é simplesmente desenvolver modelos mais robustos. É construir um fluxo de trabalho completo em torno deles — reconstruir cenas do mundo real, gerar cenários de casos extremos, treinar políticas, avaliar [...]

5 formas como o Google Search pode aprimorar suas compras de itens de segunda mão e vintage
Descubra achados de segunda mão com ferramentas de IA no Google Search e Shopping.

Otimização de Preferência Direta para Além dos Chatbots
Otimização de Preferência Direta para Além dos Chatbots

Agenda de políticas públicas da OpenAI
A OpenAI apresenta sua agenda de políticas públicas para AI, incluindo segurança, proteção da juventude, transição da força de trabalho e padrões globais para garantir que a AI beneficie a sociedade.

Adicionando Ferramentas MCP ao Reachy Mini
Adicionando Ferramentas MCP ao Reachy Mini
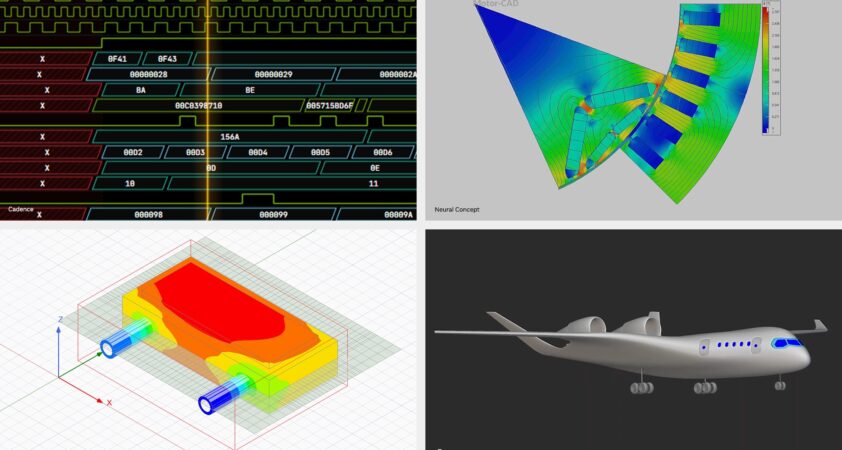
Líderes de Software Industrial Criam "Engenheiros" de IA Autônomos e Seguros com NVIDIA NemoClaw
A computação acelerada revolucionou a engenharia industrial, comprimindo os tempos de simulação de semanas para horas. Os desafios restantes hoje residem no fluxo de trabalho de ponta a ponta que cerca as simulações: projeto auxiliado por computador, geração de malha, configuração e depuração de simulações, bem como pós-processamento e geração de relatórios de resumo desses processos. Na GTC Taipei, na COMPUTEX, a NVIDIA e mais de uma dúzia de softwares de engenharia […]
NVIDIA Faz Parceria com Microsoft em Pilha Unificada para Implantação de IA Agente, de Dispositivos Windows à Nuvem e Local
O momento da IA agente chegou, mas cumprir sua promessa exige mais do que bons modelos. Também requer hardware rápido, runtimes seguros, uma camada de dados responsiva e modelos ajustados para raciocínio de longa duração. NVIDIA e Microsoft estão trazendo essa pilha completa para desenvolvedores em dispositivos Windows, nuvem Azure e implantações locais. Na Microsoft Build, a NVIDIA […]

Holo3.1: Agentes Rápidos e Locais para Uso de Computador
Holo3.1 é uma nova geração de agentes de IA projetados para interação rápida e local com computadores. Este avanço representa um passo significativo para tornar a automação assistida por IA mais acessível e eficiente para usuários cotidianos, operando diretamente no hardware local, em vez de depender exclusivamente da nuvem.

Por que as Instituições Financeiras Estão Convergindo para Modelos de Fundação de Transações para Construir Sua Própria Inteligência
As instituições financeiras passaram anos construindo IA: modelos de fraude, modelos de crédito, mecanismos de recomendação e sistemas de risco. Embora essa proliferação de modelos específicos para tarefas tenha sido eficaz, ela também é limitada por sistemas isolados. Sistemas isolados impedem que as instituições desenvolvam uma compreensão unificada do comportamento financeiro dos consumidores. À medida que os conjuntos de dados corporativos continuam a crescer, o mesmo acontece com a lacuna entre o que [... ainda por chegar ao seu final]

NVIDIA Jetson Leva a IA Agente para o Mundo Físico
A IA agente está se tornando física. Na COMPUTEX, na terça-feira, a NVIDIA anunciou o NVIDIA JetPack 7.2 e o suporte ao NVIDIA NemoClaw no NVIDIA Jetson. O JetPack 7.2 traz habilidades de IA agente, suporte ao projeto Yocto, NVIDIA CUDA 13 no NVIDIA Jetson Orin, um ganho substancial de desempenho no módulo Jetson AGX Orin de 32 GB e suporte a Multi-Instance GPU (MIG) no NVIDIA Jetson [...]
Codex está se tornando uma ferramenta de produtividade para todos
O relatório "A Próxima Era do Trabalho do Conhecimento" explora como o Codex está transformando a produtividade através de pesquisa alimentada por AI, análise de dados, automação de fluxo de trabalho e criação de conteúdo.

Como usamos o Gemini para construir o Google I/O 2026
<img src="https://storage.googleapis.com/gweb-uniblog-publish-prod/images/AI_IO.max-600x600.format-webp.webp">Saiba como os Googlers usaram AI para produzir o Google I/O 2026.

Apresentando Mellum2: Um Modelo Mixture-of-Experts de 12B da JetBrains
A JetBrains lançou o Mellum2, um modelo Mixture-of-Experts (MoE) com 12 bilhões de parâmetros. Este novo modelo representa um avanço significativo no campo da inteligência artificial, oferecendo maior eficiência e desempenho em comparação com modelos densos tradicionais de tamanho semelhante. O Mellum2 é projetado para otimizar a utilização de recursos computacionais, tornando-o ideal para aplicações que exigem alta capacidade de processamento com menor custo operacional.

Ecossistema NVIDIA AI Cloud se Expande Globalmente para Atender à Demanda Mundial por Computação de IA
O ecossistema NVIDIA AI Cloud está acelerando a construção global da infraestrutura de "fábricas de IA". Parceiros estão expandindo a capacidade para atender à crescente demanda de empresas, startups, nações, laboratórios de IA e desenvolvedores que escalam aplicações de IA agentificada. As NVIDIA AI Clouds são um ecossistema crescente de nuvens construídas especificamente para atender à demanda explosiva por tokens por trás das aplicações de IA mais populares da atualidade. [...]

NVIDIA Factory Operations Blueprint Dá às Fábricas um Novo Cérebro de IA
À medida que as fábricas transitam da automação isolada para a inteligência de toda a planta, os fabricantes precisam de sistemas de IA que possam conectar sinais de máquinas em tempo real, sistemas de qualidade, instruções de trabalho e alertas operacionais em uma camada de decisão unificada. Hoje, na GTC Taipei na COMPUTEX, a NVIDIA anunciou o NVIDIA Factory Operations Blueprint (FOX) — um design de referência para construir um gerente de fábrica autônomo […]
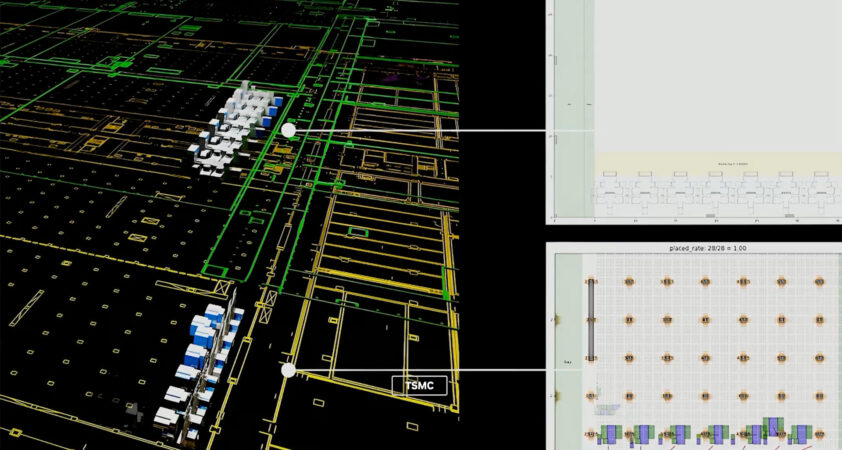
Titãs da Indústria de Taiwan Turbinam a Construção da Infraestrutura de IA Mundial com a NVIDIA
Taiwan abriga mais de 500 parceiros do ecossistema NVIDIA. Mais de 1 milhão de componentes de rack NVIDIA MGX para a infraestrutura NVIDIA Vera Rubin são montados em Taiwan, em 25 fábricas. À medida que o Vera Rubin acelera para produção total para alimentar fábricas de IA agentless em todo o mundo, esse ecossistema abrange toda a cadeia de suprimentos — desde os principais [...].

Como o Cosmos 3 Ajuda a IA Física a Pensar Antes de Agir
Cosmos 3 é uma arquitetura de IA que permite que a IA física tome decisões mais inteligentes antes de agir, simulando resultados potenciais.

NVIDIA Eleva o Nível dos Agentes AI Locais em PCs RTX e DGX Spark
Agentes pessoais estão explodindo em popularidade, com projetos de código aberto como OpenClaw e Hermes vendo rápida adoção pelas comunidades de desenvolvedores de AI no GitHub. Construídos para se adaptar às preferências e fluxos de trabalho individuais, esses agentes podem interagir com aplicativos, gerar conteúdo, automatizar processos repetitivos e gerenciar tarefas de várias etapas — tudo enquanto são executados localmente no dispositivo. Hoje em [...]

SoftBank anuncia investimento de até €75 bilhões para construir data centers na França
O objetivo, segundo a empresa, é desenvolver e operar até 5 gigawatts de capacidade adicional de data centers.

“Que piada”: A nova cobrança baseada em tokens do Github Copilot gera consternação entre desenvolvedores
A era de ouro do Github Copilot da Microsoft parece ter chegado ao fim.

Meta estaria desenvolvendo um pingente de IA
A Meta parece estar fazendo grandes apostas em hardware com tecnologia de IA.

Coloquei o assistente de IA 24 horas por dia, 7 dias por semana, Gemini Spark, para trabalhar, e ele é realmente muito útil
O Gemini Spark ajuda a automatizar tarefas cotidianas, desde resumos de caixa de entrada até o planejamento de eventos locais, mas não está claro por que o Google o tornou um produto separado.

A medida que a guerra dos navegadores esquenta, aqui estão as alternativas mais populares ao Chrome e Safari em 2026
Compilamos uma visão geral de alguns dos principais navegadores alternativos disponíveis hoje que visam desafiar o Chrome e o Safari.

Programadores estão se recusando a trabalhar sem AI — e isso pode se voltar contra eles
Embora a AI esteja ajudando os programadores a produzir código mais rapidamente, ela pode não estar produzindo um código melhor, alertam pesquisadores. E isso pode causar problemas para eles no futuro.

Faça nosso quiz do I/O 2026, codificado no Google AI Studio.
Criamos um quiz divertido sobre os principais anúncios do I/O 2026 usando o Google AI Studio.

Então você ouviu esses termos de IA e apenas balançou a cabeça; vamos mudar isso
A ascensão da IA trouxe uma avalanche de novos termos e gírias. Aqui está um glossário com definições de algumas das palavras e frases mais importantes que você pode encontrar.

O que acontece quando as empresas se tornam 'AI-pilled' demais?
As pessoas que decidem que a IA pode substituir seu trabalho também são as menos propensas a entender o que seu trabalho realmente envolve, de acordo com o fundador da Box, Aaron Levie, que apontou isso como um exemplo de “psicose de IA”. De fato, a ClickUp recentemente cortou 22% de sua força de trabalho para agentes de IA, as demissões em tecnologia em 2026 já estão quase igualando todo o ano de 2025, [...]
Quer ver mais notícias?
O catálogo completo com busca avançada e filtros está disponível no app
Ver todas as notícias →