Este Artigo de IA Apresenta o TinyLoRA, um Método de Fine-Tuning de 13 Parâmetros que Atinge 91,8% no GSM8K no Qwen2.5-7B
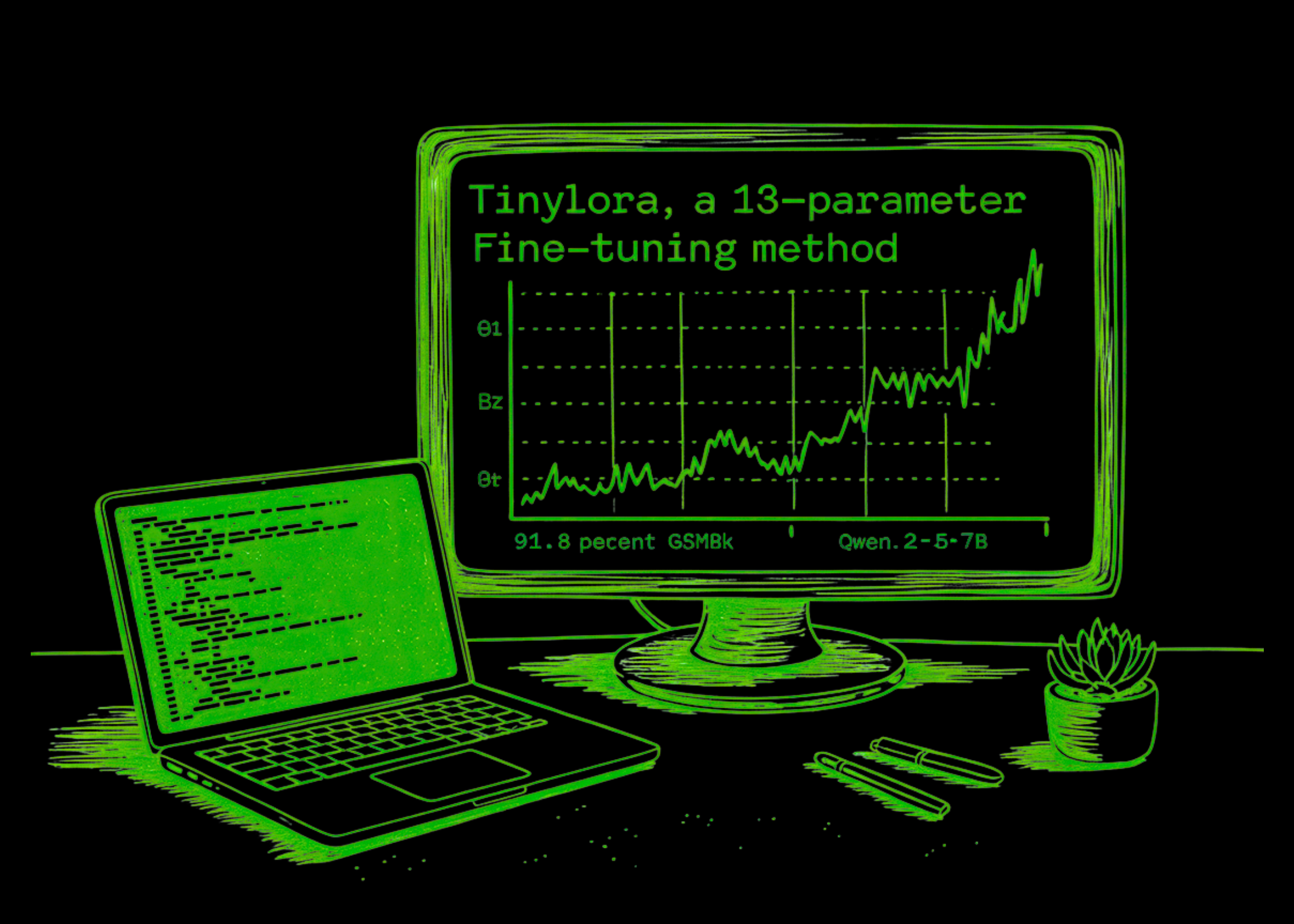
Pesquisadores da FAIR na Meta, Cornell University e Carnegie Mellon University demonstraram que modelos de linguagem grandes (LLMs) podem aprender a raciocinar usando um número notavelmente pequeno de parâmetros treinados. A equipe de pesquisa apresenta o TinyLoRA, uma parametrização que pode ser reduzida a um único parâmetro treinável em configurações de compartilhamento extremas. Usando este método em um […] A postagem Este AI
Pesquisadores da FAIR na Meta, Cornell University e Carnegie Mellon University demonstraram que modelos de linguagem grandes (LLMs) podem aprender a raciocinar usando um número notavelmente pequeno de parâmetros treinados. A equipe de pesquisa apresenta o TinyLoRA, uma parametrização que pode ser reduzida a um único parâmetro treinável em configurações de compartilhamento extremas. Usando este método em um backbone Qwen2.5-7B-Instruct, a equipe de pesquisa alcançou 91,8% de precisão no benchmark GSM8K com apenas 13 parâmetros, totalizando apenas 26 bytes em bf16. Superando as Restrições do LoRA Padrão O LoRA (Low-Rank Adaptation) padrão adapta uma camada linear congelada W ∈ R d x k usando matrizes treináveis A ∈ R d x r e B ∈ R r x k. A contagem de parâmetros treináveis no LoRA padrão ainda escala com a largura e a patente da camada, o que deixa um limite inferior não trivial mesmo com patente 1. Para um modelo como o Llama3-8B, este tamanho mínimo de atualização é de aproximadamente 3 milhões de parâmetros. O TinyLoRA contorna isso, baseando-se no LoRA-XS, que utiliza a Decomposição de Valor Singular (SVD) truncada de pesos congelados. Enquanto o LoRA-XS normalmente requer pelo menos um parâmetro por módulo adaptado, o TinyLoRA substitui a matriz treinável por um vetor treinável de baixa dimensão 𝜐 ∈ R u projetado através de um tensor aleatório fixo P ∈ R u x r x r. A regra de atualização é definida como: $$W’ = W + U\Sigma(\sum_{i=1}^{u}v_{i}P_{i})V^{\top}$$ Ao aplicar um fator de amarração de peso (n tie), os parâmetros treináveis totais escalam como O(nmu/n tie), permitindo que as atualizações escalem para um único parâmetro quando todos os módulos em todas as camadas compartilham o mesmo vetor. Aprendizado por Reforço: O Catalisador para Atualizações Mínimas Uma descoberta central da pesquisa é que o Aprendizado por Reforço (RL) é fundamentalmente mais eficiente do que o Fine-tuning Supervisionado (SFT) em contagens de parâmetros extremamente baixas. A equipe de pesquisa informa que os modelos treinados via SFT exigem atualizações 100 a 1.000 vezes maiores para atingir o mesmo desempenho que aqueles treinados com RL. Essa lacuna é atribuída à 'densidade de informação' do sinal de treinamento. O SFT força um modelo a absorver muitos bits de informação – incluindo ruído estilístico e estruturas irrelevantes de demonstrações humanas – porque seu objetivo trata todos os tokens como igualmente informativos. Em contraste, o RL (especificamente a Otimização de Política Relativa de Grupo ou GRPO) fornece um sinal mais esparso, mas mais limpo. Como as recompensas são binárias (por exemplo, correspondência exata para uma resposta matemática), os recursos relevantes para a recompensa se correlacionam com o sinal, enquanto os irrelevantes