Hugging Face Lanca TRL v1.0: Uma Stack Unificada de Pós-Treinamento para Workflows de SFT, Modelagem de Recompensa, DPO e GRPO
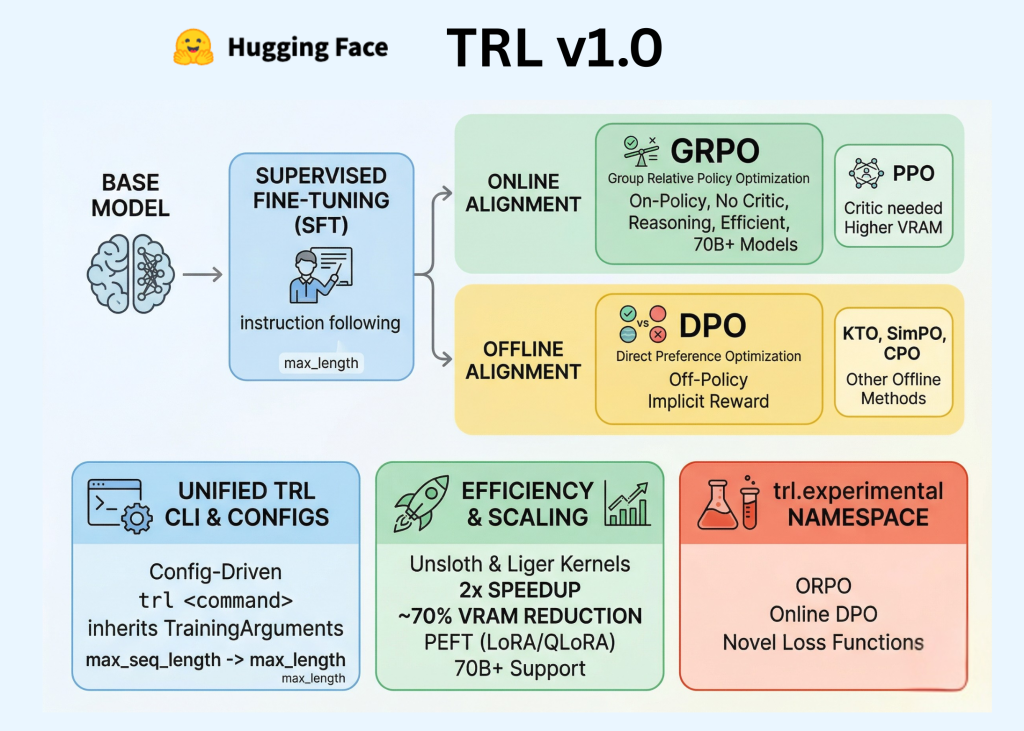
Hugging Face lançou oficialmente o TRL (Transformer Reinforcement Learning) v1.0, marcando uma transição fundamental para a biblioteca, de um repositório orientado à pesquisa para um framework estável e pronto para produção. Para profissionais e desenvolvedores de IA, este lançamento codifica o pipeline de Pós-Treinamento — a sequência essencial de Supervised Fine-Tuning (SFT), Modelagem de Recompensa e Alinhamento — em um sistema unificado.
A Hugging Face lançou oficialmente o TRL (Transformer Reinforcement Learning) v1.0, marcando uma transição fundamental para a biblioteca, de um repositório orientado à pesquisa para um framework estável e pronto para produção. Para profissionais e desenvolvedores de IA, este lançamento codifica o pipeline de Pós-Treinamento — a sequência essencial de Supervised Fine-Tuning (SFT), Modelagem de Recompensa e Alinhamento — em uma API unificada e padronizada. Nos estágios iniciais do boom de LLMs, o pós-treinamento era frequentemente tratado como uma 'arte obscura' experimental. O TRL v1.0 visa mudar isso, fornecendo uma experiência consistente para o desenvolvedor, construída em três pilares principais: uma Interface de Linha de Comando (CLI) dedicada, um sistema de Configuração unificado e um conjunto expandido de algoritmos de alinhamento, incluindo DPO, GRPO e KTO. A Stack Unificada de Pós-Treinamento é a fase em que um modelo base pré-treinado é refinado para seguir instruções, adotar um tom específico ou exibir capacidades complexas de raciocínio. O TRL v1.0 organiza esse processo em estágios distintos e interoperáveis: Supervised Fine-Tuning (SFT): A etapa fundamental onde o modelo é treinado em dados de alta qualidade de seguimento de instruções para adaptar seu conhecimento pré-treinado a um formato conversacional. Modelagem de Recompensa: O processo de treinamento de um modelo separado para prever as preferências humanas, que atua como um 'juiz' para pontuar diferentes respostas do modelo. Alinhamento (Aprendizado por Reforço): O refinamento final onde o modelo é otimizado para maximizar as pontuações de preferência. Isso é alcançado por meio de métodos 'online' que geram texto durante o treinamento ou métodos 'offline' que aprendem a partir de conjuntos de dados de preferência estáticos. Padronizando a Experiência do Desenvolvedor: A CLI do TRL Uma das atualizações mais significativas para engenheiros de software é a introdução de uma CLI robusta do TRL. Anteriormente, os engenheiros eram obrigados a escrever um extenso código repetitivo (boilerplate) e loops de treinamento personalizados para cada experimento. O TRL v1.0 introduz uma abordagem orientada por configuração que utiliza arquivos YAML ou argumentos diretos de linha de comando para gerenciar o ciclo de vida do treinamento. O Comando trl A CLI oferece pontos de entrada padronizados para os principais estágios de treinamento. Por exemplo, iniciar uma execução de SFT agora pode ser executado por meio de um único comando: Copiar Código Copiado Usar um navegador diferente trl sft --model_name_or_path meta-llama/Llama-3.1-8B --dataset_name openbmb/UltraInteract --output_dir ./sft_results Esta interface é integrada com o Hugging Face Accelerate, o que permite o mesmo.