Meta Superintelligence Lab Lança Muse Spark: Um Modelo de Raciocínio Multimodal com Compressão de Pensamento e Agentes Paralelos
A Meta Superintelligence Labs recentemente deu um passo significativo ao apresentar o 'Muse Spark' — o primeiro modelo da família Muse. O Muse Spark é um modelo de raciocínio nativamente multimodal com suporte para uso de ferramentas, cadeia de pensamento visual e orquestração multiagente. O que 'Nativamente Multimodal' Realmente Significa Quando a Meta descreve o Muse Spark como 'nativamente multimodal', isso significa que ele
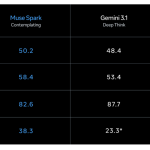
A Meta Superintelligence Labs recentemente deu um passo significativo ao apresentar o 'Muse Spark' — o primeiro modelo da família Muse. O Muse Spark é um modelo de raciocínio nativamente multimodal com suporte para uso de ferramentas, cadeia de pensamento visual e orquestração multiagente. https://ai.meta.com/static-resource/muse-spark-eval-methodology O Que 'Nativamente Multimodal' Realmente Significa Quando a Meta descreve o Muse Spark como 'nativamente multimodal', isso significa que o modelo foi treinado desde o início para processar e raciocinar com entradas de texto e visuais simultaneamente — não um módulo de visão acoplado a um modelo de linguagem posteriormente. O Muse Spark é construído desde o início para integrar informações visuais em diversos domínios e ferramentas, alcançando um forte desempenho em questões visuais de STEM, reconhecimento de entidades e localização. Essa escolha arquitetônica tem consequências reais em tarefas que combinam linguagem e visão. No benchmark ScreenSpot Pro — que testa a localização de capturas de tela, exigindo que o modelo identifique elementos específicos da interface do usuário em imagens — o Muse Spark pontua 72,2 (84,1 com ferramentas Python), em comparação com o 57,7 do Claude Opus 4.6 Max (83,1 com Python) e o 39,0 do GPT-5.4 Xhigh (85,4 com Python). Três Eixos de Escalabilidade: Pré-treinamento, RL e Raciocínio em Tempo de Teste A parte mais interessante tecnicamente do anúncio do Muse Spark é o enquadramento explícito da Meta em torno de três eixos de escalabilidade — as alavancas que eles estão usando para melhorar a capacidade do modelo de forma previsível e mensurável. Para apoiar uma maior escalabilidade em todos os três, a Meta está fazendo investimentos estratégicos em todo o stack — desde pesquisa e treinamento de modelos até infraestrutura, incluindo o data center Hyperion. O pré-treinamento é onde o modelo aprende seu conhecimento central do mundo, raciocínio e habilidades de codificação. Nos últimos nove meses, a Meta reconstruiu seu stack de pré-treinamento com melhorias na arquitetura do modelo, otimização e curadoria de dados. O resultado são ganhos substanciais de eficiência: a Meta pode alcançar as mesmas capacidades com uma ordem de magnitude menos computação do que seu modelo anterior, Llama 4 Maverick. Para os desenvolvedores, 'uma ordem de magnitude' significa aproximadamente 10 vezes mais eficiente em termos de computação — uma melhoria importante que torna modelos futuros maiores mais viáveis financeira e praticamente. O Aprendizado por Reforço (RL) é o segundo eixo. Após o pré-treinamento, o RL é aplicado para amplificar as capacidades, treinando o modelo com feedback baseado em resultados, em vez de apenas previsão de tokens. Pense nisso dessa forma