Pesquisa de IA da Salesforce Lança o VoiceAgentRAG: Um Roteador de Memória de Agente Duplo que Reduz a Latência de Recuperação de RAG de Voz em 316x
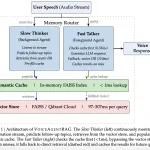
No mundo da IA de voz, a diferença entre um assistente útil e uma interação estranha é medida em milissegundos. Enquanto os sistemas de Geração Aumentada por Recuperação (RAG) baseados em texto podem ter alguns segundos de tempo de 'pensamento', os agentes de voz devem responder dentro de um orçamento de 200 ms para manter um fluxo conversacional natural. Consultas padrão de banco de dados vetorial de produção geralmente adicionam [...]
No mundo da IA de voz, a diferença entre um assistente útil e uma interação estranha é medida em milissegundos. Enquanto os sistemas de Geração Aumentada por Recuperação (RAG) baseados em texto podem ter alguns segundos de tempo de 'pensamento', os agentes de voz devem responder dentro de um orçamento de 200 ms para manter um fluxo conversacional natural. Consultas padrão de banco de dados vetorial de produção geralmente adicionam 50-300 ms de latência de rede, consumindo efetivamente todo o orçamento antes mesmo de um LLM começar a gerar uma resposta. A equipe de pesquisa de IA da Salesforce lançou o VoiceAgentRAG, uma arquitetura de agente duplo de código aberto projetada para contornar esse gargalo de recuperação, desacoplando a busca de documentos da geração de resposta. https://arxiv.org/pdf/2603.02206 A Arquitetura de Agente Duplo: Falador Rápido vs. Pensador Lento O VoiceAgentRAG opera como um roteador de memória que orquestra dois agentes concorrentes através de um barramento de eventos assíncrono: O Falador Rápido (Agente de Primeiro Plano): Este agente lida com o caminho crítico de latência. Para cada consulta do usuário, ele primeiro verifica um Cache Semântico local, em memória. Se o contexto necessário estiver presente, a consulta leva aproximadamente 0,35 ms. Em caso de cache miss, ele recorre ao banco de dados vetorial remoto e imediatamente armazena os resultados em cache para futuras interações. O Pensador Lento (Agente de Segundo Plano): Executando como uma tarefa em segundo plano, este agente monitora continuamente o fluxo da conversa. Ele usa uma janela deslizante das últimas seis interações da conversa para prever 3 a 5 tópicos de acompanhamento prováveis. Ele então pré-busca blocos de documentos relevantes do armazenamento vetorial remoto para o cache local antes mesmo que o usuário diga sua próxima pergunta. Para otimizar a precisão da pesquisa, o Pensador Lento é instruído a gerar descrições no estilo de documento, em vez de perguntas. Isso garante que os embeddings resultantes se alinhem mais de perto com a prosa real encontrada na base de conhecimento. A Espinha Dorsal Técnica: Cache Semântico A eficiência do sistema depende de um cache semântico especializado implementado com um FAISS IndexFlat IP (produto interno) em memória. Indexação de Documento-Embedding: Diferente dos caches passivos que indexam por significado da consulta, o VoiceAgentRAG indexa as entradas pelos seus próprios embeddings de documento. Isso permite que o cache execute uma pesquisa semântica adequada sobre seu conteúdo, garantindo relevância mesmo que a frase do usuário difira das previsões do sistema. Gerenciamento de Limite: Como a similaridade de cosseno de consulta para documento é sistematicamente menor do que a similaridade de consulta para consulta, o sistema usa