Tongyi Lab da Alibaba Lança VimRAG: um Framework RAG Multimodal que Usa um Grafo de Memória para Navegar em Contextos Visuais Massivos
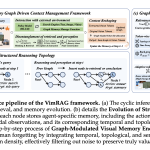
A Geração Aumentada por Recuperação (RAG) se tornou uma técnica padrão para fundamentar grandes modelos de linguagem em conhecimento externo — mas no momento em que você vai além do texto simples e começa a misturar imagens e vídeos, toda a abordagem começa a falhar. Dados visuais são pesados em tokens, semanticamente esparsos em relação a uma consulta específica e rapidamente se tornam inadministráveis durante várias etapas [...] A postagem Alibaba'
A Geração Aumentada por Recuperação (RAG) tornou-se uma técnica padrão para fundamentar grandes modelos de linguagem em conhecimento externo — mas no momento em que você vai além do texto simples e começa a misturar imagens e vídeos, toda a abordagem começa a falhar. Dados visuais são pesados em tokens, semanticamente esparsos em relação a uma consulta específica e rapidamente se tornam inadministráveis durante um raciocínio multi-etapas. Pesquisadores do Tongyi Lab, do Alibaba Group, apresentaram o 'VimRAG', um framework construído especificamente para resolver essa falha. O problema: histórico linear e memória comprimida falham com dados visuais. A maioria dos agentes RAG hoje segue um loop de Pensamento-Ação-Observação — às vezes chamado de ReAct — onde o agente anexa todo o seu histórico de interação em um único contexto crescente. Formalmente, na etapa t, o histórico é H t = [q, τ 1 , a 1 , o 1 , ..., τ t-1 , a t-1 , o t-1 ]. Para tarefas que envolvem vídeos ou documentos visualmente ricos, isso rapidamente se torna insustentável: a densidade de informação de observações críticas |O crit |/|H t | tende a zero conforme as etapas de raciocínio aumentam. A resposta natural é a compressão baseada em memória, onde o agente resume iterativamente as observações passadas em um estado compacto mt. Isso mantém a densidade estável em |O crit |/|m t | ≈ C, mas introduz a cegueira Markoviana — o agente perde o controle do que já consultou, levando a buscas repetitivas em cenários de múltiplos saltos. Em um estudo piloto comparando ReAct, sumarização iterativa e memória baseada em grafo usando Qwen3VL-30B-A3B-Instruct em um corpus de vídeo, agentes baseados em sumarização sofreram de cegueira de estado tanto quanto o ReAct, enquanto a memória baseada em grafo reduziu significativamente as ações de busca redundantes. Um segundo estudo piloto testou quatro estratégias de memória de modalidade cruzada. A pré-captioning (texto → texto) usa apenas 0,9k tokens, mas atinge apenas 14,5% nas tarefas de imagem e 17,2% nas tarefas de vídeo. Armazenar tokens visuais brutos usa 15,8k tokens e atinge 45,6% e 30,4% — ruído oprime o sinal. A captioning sensível ao contexto comprime para texto e melhora para 52,8% e 39,5%, mas perde detalhes finos necessários para verificação. Retendo seletivamente apenas os tokens de visão relevantes — Memória Visual Semanticamente Relacionada — usa 2,7k tokens e atinge 58,2% e 43,7%, o melhor custo-benefício. Um terceiro estudo piloto sobre atribuição de crédito descobriu que em trajetórias positivas (recompensa = 1), aproximadamente 80% das etapas contêm ruído que receberia incorretamente um sinal de gradiente positivo sob o RL baseado em resultados padrão, e que a remoção de etapas redundantes de nega